Le secret pour sécuriser les données d'entreprise tout en utilisant l'IA générative ? Demandez à Guardian.
24 janvier 2025
Exploiter la puissance de l'IA générative pour améliorer l'efficacité et réduire les coûts sans compromettre la sécurité des données.
L'IA générative est en train de se généraliser, s'intégrant dans les processus métier des entreprises et promettant des opérations optimisées et des économies de coûts. Cependant, les inquiétudes concernant l'exposition de données sensibles aux grands modèles de langage (LLM) ont fait hésiter les organisations à adopter la technologie - en particulier lorsqu'il s'agit d'informations critiques sur leurs processus, leur technologie et leurs utilisateurs.
Une étude récente de Cisco a révélé que plus d'une organisation sur quatre a interdit l'IA générative en raison de préoccupations liées à la protection de la vie privée et à la sécurité des données. Cela met en évidence la tension importante entre le désir d'innover avec l'IA et le besoin critique de protéger les données de l'entreprise.
Exploration des risques d'exposition aux données
Les organisations sont confrontées à des défis uniques en matière de protection de deux types de données :
- Données structurées: Stockés dans des bases de données relationnelles sous forme de tableaux et de colonnes.
- Données non structurées: Présents dans les documents, les politiques, les processus, les images et les articles sur les connaissances.
Les LLM ont besoin d'accéder aux données pour apprendre et générer des résultats pertinents sur le plan contextuel. Cependant, l'exposition des données de l'entreprise aux LLM présente des risques supplémentaires, comme l'illustrent les scénarios suivants :
Scénario 1 : Exposition de données commerciales sensibles
Imaginons qu'un fournisseur de progiciels de gestion intégrés (ERP) utilise des LLM pour faciliter la génération de factures basées sur le NLP. En fournissant des données sensibles telles que les numéros de pièces, les prix unitaires et les politiques de remise, l'organisation risque une exposition indirecte. Si un autre utilisateur demande "Quelle est la remise habituelle pour les organisations à but non lucratif ?", il pourrait révéler par inadvertance des informations sensibles apprises par le LLM.
Le présent problème d'exposition des données se produit lorsque les gestionnaires de l'apprentissage à long terme utilisent involontairement des informations apprises en dehors du contexte prévu, ce qui entraîne des risques potentiels pour l'entreprise.
Scénario 2 : Violations de la conformité dans différentes zones géographiques
Les organisations opérant dans plusieurs régions doivent respecter des réglementations strictes en matière de confidentialité des données et de localisation. Par exemple, les IIP des employés européens ne peuvent pas être partagées en dehors de l'Europe. L'exposition de ces données aux LLM pourrait constituer une violation de la législation sur la protection des données. accords sur le traitement des données et de franchir les limites de la réglementation et de la conformité.
Menaces et vulnérabilités émergentes
L'évolution de l'IA générative s'accompagne d'une augmentation des risques. Les premiers utilisateurs doivent prendre en compte les vulnérabilités des infrastructures, des réseaux et des applications. Quelques risques notables inclure :
- Fuites de données LLM: Révélations involontaires d'informations propriétaires sensibles
- Attaques par injection rapide: Requêtes manipulatrices conçues pour extraire des données confidentielles
- Modèle Vol: L'accès non autorisé ou la falsification des modèles LLM
Les outils actuels et leurs limites
Bien que les fournisseurs de LLM et les sociétés tierces proposent des outils pour la sécurité des données, ces solutions se concentrent principalement sur les données non structurées (comme les documents). Souvent, elles n'abordent pas le problème fondamental de l'exposition des données structurées.
Par exemple, les techniques de masquage des données peuvent masquer les informations sensibles pendant la formation des gestionnaires de l'apprentissage tout au long de la vie. Toutefois, elles n'empêchent pas les gestionnaires de l'apprentissage à distance d'apprendre par inadvertance des tendances ou des moyennes susceptibles d'être utilisées à mauvais escient au-delà des frontières de l'organisation.
Une solution holistique : L'approche d'Alert Enterprise
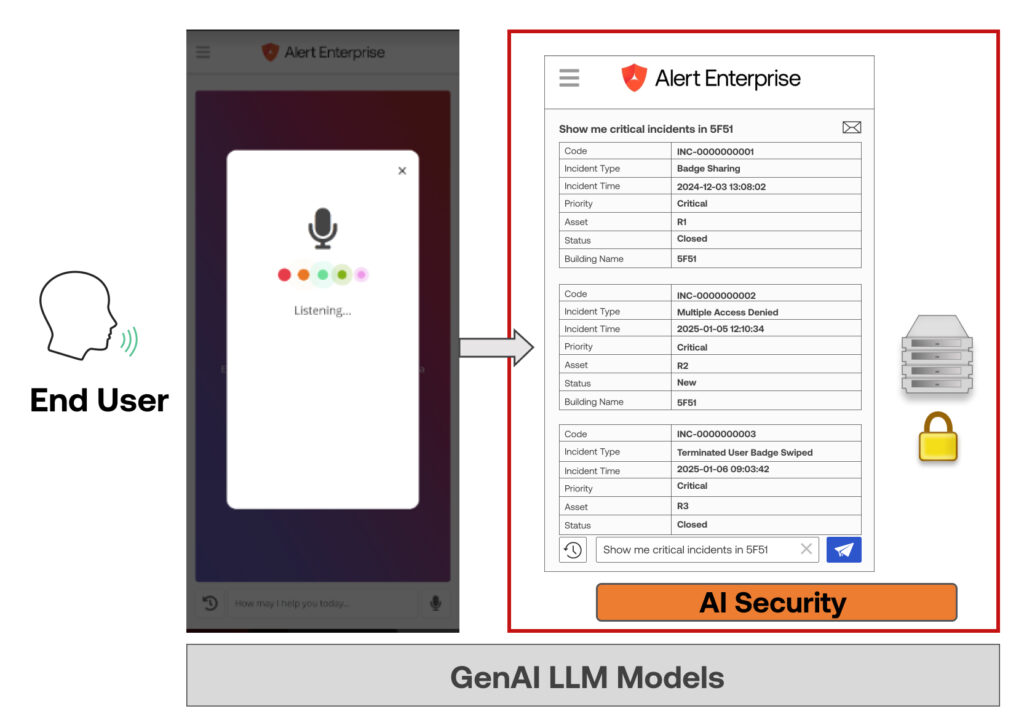
Le moyen le plus efficace de sécuriser les données de l'entreprise est d'empêcher totalement les LLM d'accéder aux données structurées réelles. Alert Enterprise a mis au point une technologie brevetée qui permet d'atteindre cet objectif en exposant les LLM uniquement aux éléments suivants métadonnées, telles que les structures de table et les entités. Le LLM utilise le traitement du langage naturel (NLP) pour convertir les requêtes en métadonnées, que l'application traduit ensuite en syntaxe lisible par la machine pour extraire les données en toute sécurité.
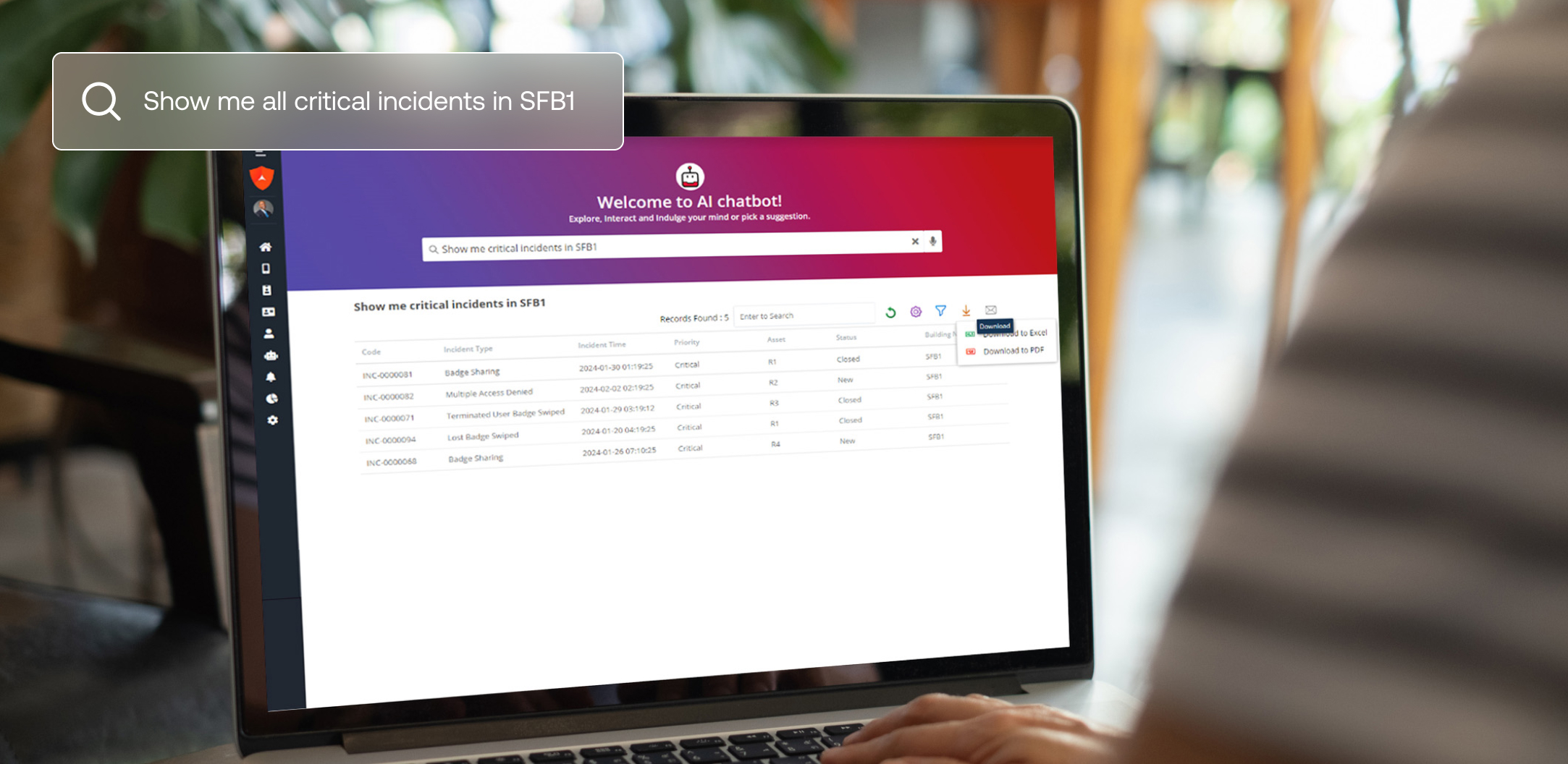
Notre Guardian Security AI Chatbot s'appuie sur cette technologie et permet aux utilisateurs de poser des questions d'analyse de données en langage naturel. Le chatbot fournit des réponses instantanées et précises sans compromettre les données sensibles.
Cette approche innovante garantit :
- Les LLM n'ont jamais accès aux données brutes, ce qui élimine les risques d'exposition.
- Les entreprises conservent un contrôle total sur leurs données structurées et maintiennent la conformité entre les régions et les départements.
Vous voulez en savoir plus ?
Découvrez notre brevet révolutionnaire sur la confidentialité des données de l'IA générative ici.





